【编者按】2021年12月11日,由雷峰网 & AI 掘金志主办的第四届中国人工智能安防峰会,在深圳正式召开。本届峰会以「数字城市的时代突围」为主题,

2021年12月11日,由雷峰网 & AI 掘金志主办的第四届中国人工智能安防峰会,在深圳正式召开。
本届峰会以「数字城市的时代突围」为主题,会上代表城市AIoT的14家标杆企业,为现场和线上观众,分享迎接数字城市的经营理念与技术应用方法论。
在下午场的演讲环节中,云天励飞首席科学家王孝宇发表了精彩演讲。
王孝宇认为,AI的研发模式有两大关键点:一是用什么样的数据训练模型;二是模型如何基于数据得到更好的结果。
过去的研发模式大都以模型为中心,依赖专家,找数据、标注数据,然后让AI博士调参,如同工业化时代的“拧螺丝钉”,导致AI无法大规模产业化。
同时,过去的研发范式,大都集中于用更好的技术建立更好的模型。但几年之后,业界发现所用的技术越来越趋同,标准化的条件成熟了
事实上,对比不同研发模型,可以发现对AI研发和应用来说,高效地获取最好的数据,比模型本身要重要得多。
究其原因是技术迭代快,容易被赶上,但数据迭代慢,因此如何在最短时间内得到可以使模型达到最优效果的数据集,这才是最重要的。
因此鉴于人力成本和模型标准化条件的成熟,云天励飞在内部打造了一套标准化、流程化、平台化的模型研发方式。
云天励飞大规模算法研发的流程是:
第一步,获取初始模型。通过分布式标注平台定义任务,再利用被千亿、百亿级的数据训练出来的大模型和无监督学习,配合少量数据的标注,得到不错的初始模型。
第二步,数据迭代。在海量还没有标注好的数据中,用技术、算法找到真正有用的数据,用主动学习算法做数据择优。
第三步,模型训练。在云天励飞的平台上用一键化方式,完成调整参数、数据挖掘等工作,降低对训练模型人员的从业要求。同时让数据、研发轨迹、开发技巧都沉淀在平台上,动作可复用,流程可追溯,降低AI人员高流动性带来的负面影响。
他认为视觉AI目前还处在拓荒阶段,是一片沙漠,没有变成绿洲,只有等到其变成绿洲时,才能“长”出很多AI企业,而云天励飞建立的这套平台,就是加速沙漠变绿洲的驱动底座。
以下是王孝宇演讲全文,雷峰网AI掘金志作了不改变原意的整理与编辑:
很高兴与大家一起分享云天励飞从事AI研发十几年来总结的一套模型研发范式,我这次的演讲题目是——AI大规模产业化实践。
首先做下自我介绍。我毕业之后去了硅谷,在NEC Labs做无人车、人脸方面的研究。2015年,我和另外几人一起去洛杉矶,帮Snap公司创建了AI研究院。2017年,回国之后,我来到了云天励飞。
2017年的时候,人工智能开始火爆起来,有非常多的应用,像聊天机器人、无人车、人脸识别,健康领域,智慧家居、AR等。但是只有人脸识别有人相信,其他的,不管是业界还是投资人,都认为是骗子,觉得做不出来什么东西。
时隔五年,再回头来看行业,我觉得很有意思。聊天机器人在每个社交网络平台,像阿里、京东,现在在电商平台上都有应用。无人车,慢慢也有Robotaxi的落地,现在也有很多企业在这方面兴起。在健康领域,五年前我们还在讨论IBM沃森的失败,当时折腾了很大的动静,但现在有很多这方面的优秀企业兴起。
当时美国一些知名的AR公司也倒闭了,但现在很多公司把自己的名字改成元宇宙,又火了起来,AR又让大家看到了希望。
这些变化其实印证了我的一个观点:不要高估AI带来的改变,也不要低估AI带来的影响,我们是在这片沙漠里垦荒的一批人。
在垦荒的过程中,我们回过头来看AI,落地应用的最大瓶颈是什么?
人才太贵了。
六年前,我们招聘AI博士的时候,给到40万美金一年,光是养一群技术人员,每年的人力成本就是一个巨额数字。但是现在,这项成本正在降低,究其原因,是AI的研发模式发生了变化。
AI的研发模式,有两个关键点。首先,有什么样的数据训练模型;其次,如何用各种技术基于数据来让模型取得更好的效果。
过去,大家把重心放在模型上,需要数据就要找,不停标注,标注完以后,就是专家干的事了,天天调模型参数、损失函数、优化器,很多AI博士毕业之后就干这个事。
这个事其实跟工业化时代拧螺丝钉的工作没太大区别,但没有博士相关的学习经历,还干不了这个事,所以很难规模化、产业化。
我们之前的研发范式,都是集中用更好的技术建立更好的模型上的,但现在不是那么回事了。
12月8日,Andrej Karpathy 发了一个推文,他是李飞飞的学生,毕业之后去了特斯拉,担任无人驾驶总监。他说,现在的AI技术都趋同了,大家都一样。
什么意思?
以视觉为例,五六年前,做自然语言处理的有一套技术,做图像识别的也有一套技术,但是做了五年之后,大家发现做的技术是一样的。不管是视觉、语音还是自然语言处理,大家用的都是同一套技术框架和模型架构来解决问题。
最近,机器学习领域的国际顶尖会议NIPS也提到:慢慢的,那些通用模型的结构,已经占据所有任务的主导地位了。
这有点像通信或编码时期,大家刚开始是百花齐放的,后来慢慢的,大家都用同一套技术架构解决所有的问题,也就是走向了标准化阶段。
如果把这两个模型研发的过程放在一起做比较,我认为更重要的,不是模型有多好,而是数据有多优质。
有句话说得好:“巧妇难为无米之炊”,你的厨艺再好,没有素材做不出任何东西,所以有好的数据才是最重要的。
在云天励飞十多年的研发过程中,我们发现,如何高效地获取最好的数据,比模型本身要重要得多。
因为技术是很容易赶上的,今天这个技术不行,可能再过三个月、六个月会有新技术出现,会不停地更新迭代。但数据的迭代效率往往没那么高,而且我们也发现,在研发过程中,90%以上的时间是放在数据上的,而不是做模型。
由此带来研发观念的转变:之前我们的观念是招聘最好的人,开发最好的技术,达到最好的效果。但实际不是这样的,如何在最短的时间内,得到可以使模型达到最优效果的数据集,这才是最重要的。
云天励飞从创立到现在,从来没有一个研发任务是,把数据收集好,模型做一遍就结束了,这个模型永远要在用户的实际场景中迭代。
怎么在实际场景中迭代?
需要在做的不够好的地方,把数据收集起来。也就是说,数据集的分布会慢慢让模型的精度达到最好。
云天励飞对研发部门KPI的制定,不仅仅是训练出了多少模型,或者说模型的精度是多少。而且明确把数据集的产生作为KPI的导向之一,它其实更重要。
优秀的开发者和一般的开发者之间,对数据的认知是不一样的,优秀的开发者对数据有非常良好的认知,模型被数据cap得很明显,在最短的时间内拿到最好的数据,才能做到最好的模型精度。
为什么说模型大规模生产?
因为现在面向城市治理算法的应用,已经不仅仅是几个算法模型了。大家经常一看,有几百个模型的需求,但企业不可能招几百个人做这个事,所以需要大规模地跑这些技术,必须要有平台化的东西进行研发。
所以云天励飞在内部打造了一套标准化、流程化、平台化的研发方式。
什么叫流程化?
流程化的英文叫Streamline。不需要切换上下文就可以把所有的事情做完,现在美国的创业非常流行这样做,RPA也是同样的思路,做机器人流程自动化,把业务的流程放在无缝衔接的框架下完成。
只有在这种情况下,效率才是最高的,不需要一会儿做这个事,一会儿做那个事,频繁切换会影响工作效率。
标准化(standardization),把里面跟模型相关的非标准化的部分全部呈现在技术上,整个平台上只剩下标准化的东西。
这样做的好处是什么?容易学习,所以不需要博士做这个事情,可能本科生甚至是高中生就可以干这个事,从而把博士资源放在更紧要的地方。
平台化(platform),这也是整个软件行业的趋势。
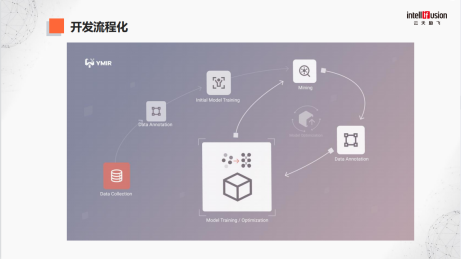
这张图是我们大规模算法研发的流程:
第一步,搜集数据,这时候数据是没有标注的。
第二步,做数据标注;
第三步,模型训练;
第四步,data mining,有了初始模型后,在海量没有标注的数据里找到可以提高性能的数据;
第五步,再进行标注。
如果把这个平台分成三步,前两步就是做初始模型的建立,后面就是做完整闭环,像飞轮一样,它在不停地转,每转一次都可以得到更好的精度。这个转法是在我们平台上实现的,不需要专家级别的人专门来做。
第一步,获取初始模型。
首先我们有分布式标注平台,开发人员可以定义一个任务。比如做街道下水道井盖有没有被人拿走的检测,也许我们会标注10-20个数据。
标注之后怎么办?这是学术界和工业界很火的大模型和无监督学习。
为什么我们在这里面放了大模型和无监督学习?刚才我们讲到,一开始我们想做井盖被人拿走的事实检测,我们一开始可能没有这么多标注好的数据,可能只有100个,但数据标注的效率可能是万分之一。
如果你想标1万个这样的数据,需要标1亿个data,这个量非常大。怎么办?
先标100个,为什么要用大模型和无监督学习配合这个数据去跑模型?就是为了让你初始模型的精度达到最高。
无监督和大模型最好的方式,本来100个数据训练出来的精度只有30%,用大模型和无监督学习的方法训练之后,精度可以达到80%,那挖掘数据的效率可以提高10倍,也就是说我少标了10倍的数据,一切都是为了后面数据迭代的效率来做的。
为什么大模型和无监督学习可以提高这个性能?虽然它自己没有标注数据,但它是被千亿、百亿级的数据训练出来的,知道井盖是什么样的,这种特征的编辑其实已经实现了,再配合少量数据的标注,就可以得到一个还不错的初始模型。
为什么要得到还不错的初始模型?因为数据迭代的效率会更高,首先是为了第一步方便。
第二步,我们不说模型迭代,而是数据迭代,因为我们认为模型的训练已经被标准化了,在平台上,点个按钮它就训练好了,不需要有模型训练的知识,我们专家的系统已经把它做好了。
所谓的数据迭代,就是在海量还没有标注好的数据中,找到能够提高模型性能的数据,进行主动学习。
传统模型研发的范式是缺数据再去标,但发现标过来的数据跟以前的分布是一样的,对模型的分布没有太大用处。所以需要用技术、算法找到对自己真正有用的数据,右边我们从海量数据中找出了9张有用的数据。
模型挖掘怎么做?在左边平台界面,点一个按钮,选一个数据集,可以自动在这里面挖掘,从几亿的数据里找到几张跟井盖相关的数据做训练,我们是用主动学习算法做数据择优的。

数据迭代之后,要做模型训练,在这个平台上用一键化的方式去做,这就是我们花几百万招过来的博士应该干的事情,他们不应该天天调参数、挖数据,这些事情应该让平台去干。
这一步,只要你点训练,它可以自动训练,背后怎么训练?是由开发者去开发的。但是在整个平台上去进行操作的人,不需要知道大规模模型训练,这降低了训练模型人员的从业要求,只要他知道这是怎么回事,把数据拿进去就可以训练,无代码一键完成模型开发。
做这种平台研发环境的好处是什么?数据沉淀在平台上,动作可复用,流程可追溯。这里面有几个界面:数据集管理、模型管理、任务管理。
数据集管理,就是一些标注好的数据集,以及挖掘、生成的数据集;模型管理,就是训练好的模型;任务管理,可以是标注任务,也可以是挖掘任务,也可以是训练任务,所有研发的轨迹全部停留在这里面。
为什么要做这个事?很简单,因为人力成本太高,企业无法招聘太多人从事每一个算法的研发。有了这套平台之后,我们可以实现非算法人员开发模型的方式,让算法工程师做更高级别的技术,这些平台话、流程化的事情,可交给一般的技术人员或者学生来做。
整个过程中,我们认为沉淀更多的是数据价值,这比模型的价值更大。
为什么数据的价值比模型的价值更大?
数据没有了,模型是训练不出来的,你不会再得到提高,即使得不到模型,数据在这儿,所以很容易再训练一个模型出来。
数据的重要性远远高于模型的重要性,所谓持续性的研发,沉淀出来的是有价值的数据,而不是其他。
因为模型很容易重新训练,或者用不同的数据迭代。但数据日积月累需要很长的时间。在整个平台上,通过数据不停的挖掘、训练、标注、迭代,会一轮一轮增加新的数据,为每个任务沉淀出非常优质的数据集。
也就是说,在这个平台上,数据变成了最重要的资产。
另外,所有的开发技巧也沉淀到平台上了。
如果大家搞研发管理,就会发现一个现象:部分人能做得特别好,部分人怎么都做不好。这是因为,任务、指令都是一样的,但不同的人研发经验是不一样的。
人才的素质属于不可控因素,如果把这套技术能力进行沉淀,每个模型研发过程都能实现可追踪,这样就能让做不好的人,通过学习,把事做好。
这样做的另一个好处是,不会因为人才流失导致既有的模型失效。
所有公司都会面临人员流动这个问题,一位优秀员工离职之后,其模型很难复现,因为别人不知道这个模型怎样迭代才达到现有的精度,上下衔接很困难,费时费力。
但是在这个平台上,就不会出现问题。模型训练过程中所做的所有数据的标注、操作,全部都在这个平台上,主要进行相关操作,全部流程都可以重复,不需要重新做。
在座如果有做研发管理的,肯定会感觉这个东西用起来非常不错。
现在,云天励飞内部的研发,除了一些非常高难度的,或者非要人工介入的算法研发(如人脸),其他的算法研发全部依赖于大规模算法开发平台。也就是说基本全部不需要算法工程师去做,都是标注人员在做。
以大堂搬运货物检测案例为例,每个工程师大概开发成本50万,一个月的时间差不多5万块钱的投入,但现在只需要1个标注人员,5-7天就可以做完从0到实用部署。
为什么能力稍微差一点,时间反而缩短了?
这就是流程化,所有模型的训练只在一个平台上完成。以前的方式,来来回回对接的成本太高,但在这个平台上,点击挖掘,自动寻找,再点标注,寻找标注人物,后台人员标注好,再点训练,全部就完成了,整个流程即使和非常有算法经验的工程师相比,这个平台也有4倍以上的提升。
我们凭借这个平台在深圳做了几个项目,像龙华智能运算能力平台。
这里面涉及的算法有上百个,公司不可能在短期内招聘几百个算法人员进行研发,因为这套平台当时还没有做得完备,所以让2个算法人员、10个标注人员,在6个月的时间把20多个算法开发全部完成了,成本也降低了很多。
为什么它需要这么多的算法?
这其实是整个城市管理思路的转变:以前是巡视型管理,需要实地巡查,才能发现、处理;现在布置相关摄像头,就能在后台发现,从而解决。
这种管理思路的转变,需要大量算法技术能力的支撑。云天励飞在龙岗算法仓做了一个项目,也是算法训练与赋能平台,这里面也有上百种算法的需求。
需要强调的是,这套研发平台没有牺牲模型的精度,不同的人群训练这套模型没有太大差别,因为在这个平台里,可以通过主动学习算法,基于数据集做快速迭代,从而得到比较高的检测精度。
最后提一点,云天励飞为什么要建立这套平台?
从行业看,视觉AI还处在拓荒阶段,仍然是一片沙漠,没有变成一片绿洲,只有等到它变成绿洲的时候,才能长出一颗颗参天大树,长出许多AI企业。
城市治理对于算法的需求是成千上万的,每个算法都靠有经验的人员去开发,成本会非常高昂,因此云天励飞开发了这套系统,缩减成本的同时,加快AI应用的进程。
可以设想,未来的城市,有一张网络可以检测方方面面,所有的事件都可以在城市大脑里解决。
这背后的技术逻辑是,算法可以做智能调度。比如对着大海的摄像头,不用把汽车检测的算法集成到摄像头上,当城市拥有一万种算法时,可以在不同场景下,调度合适的算法,来解决问题。
云天励飞的愿景是,通过知识图谱和整个平台的研发,让城市超脑实现自我进化,从而达到更高的智能化水平。
值得一提的是,云天励飞的自进化城市智能体的思路,已经被写入深圳市政府工作报告中。

